Overview
The BMMR dataset is proposed to support the evaluation and development of multimodal foundation models in college-level, multidisciplinary knowledge, understanding, and reasoning. It comprises 110k items spanning 300 UNESCO-defined subfields across 8 high-level disciplines.
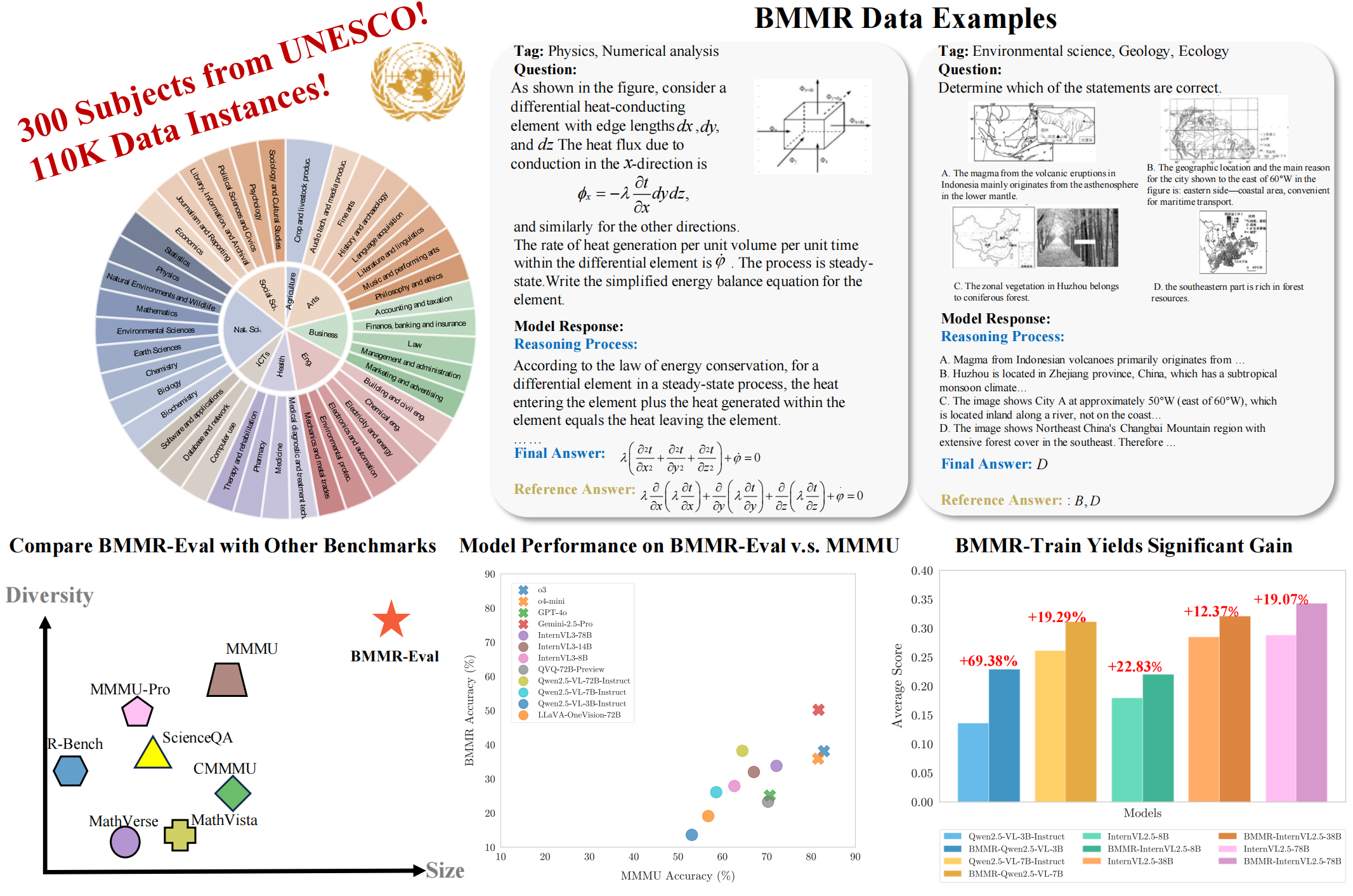
BMMR is bilingual (English and Chinese) and sourced from both print and digital media, including books, exams, and quizzes. This variety of sources inevitably introduces uncertainty in data quality. We design specific procedures to ensure question diversity, complexity, and answer verifiability. We also re-organize the original questions—through rewriting and augmentation—into multiple-choice, fill-in-the-blank, and open-ended QA formats to minimize the impact of model memorization and guessing. Each retained instance requires cross-modal understanding, domain-specific expertise, and advanced reasoning skills to solve. To support the research community, each instance is paired with a high-quality reasoning path.
BMMR is splited into two subsets: BMMR-Eval, containing 20,458 examples, and BMMR-Train, containing 88,991 examples. Specifically, BMMR-Eval is designed to comprehensively assess LMMs’ perception, knowledge, and reasoning across a broad range of disciplines and difficulty levels; BMMR-Train supports the community’s research and development of next-generation multimodal foundation models, extending the current focus of the community on mathematical reasoning to diverse disciplines and domains.
Comparisons with Existing Benchmarks
We compare our BMMR-Eval with other benchmarks regarding size and diversity(top-left). A comparison of model performance on BMMR-Eval versus MMMU is also included(top-right), highlighting the challenging nature of our test set.
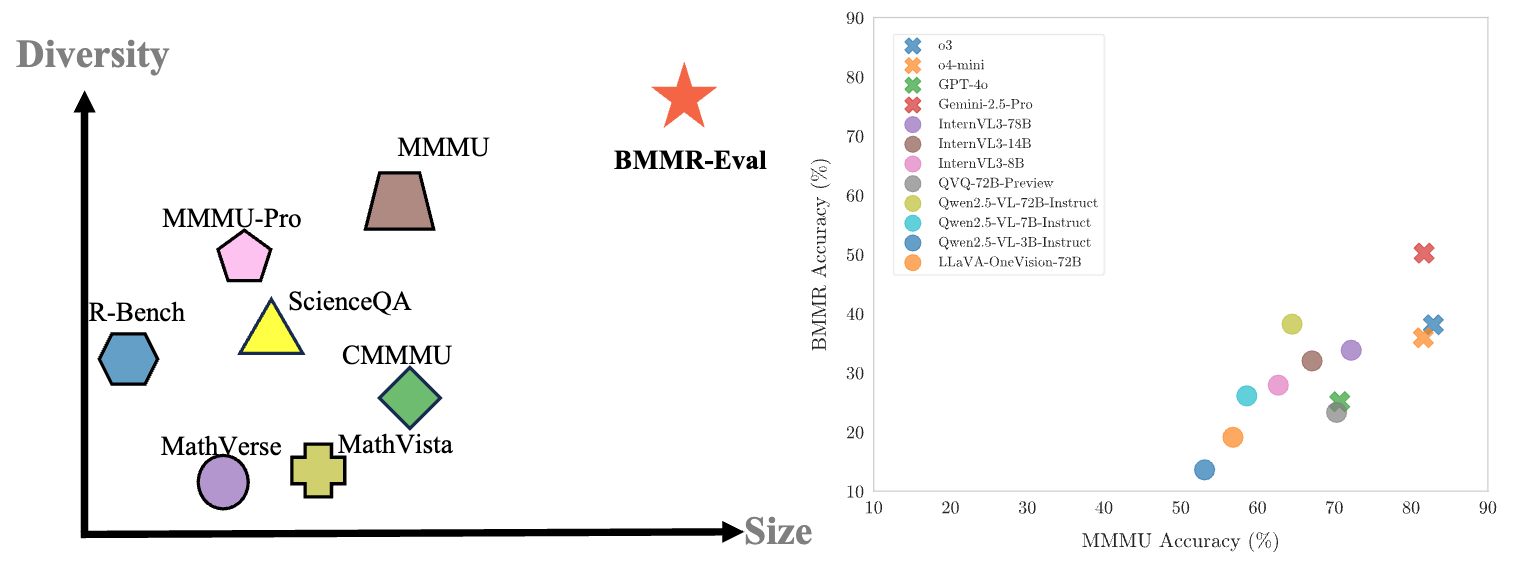
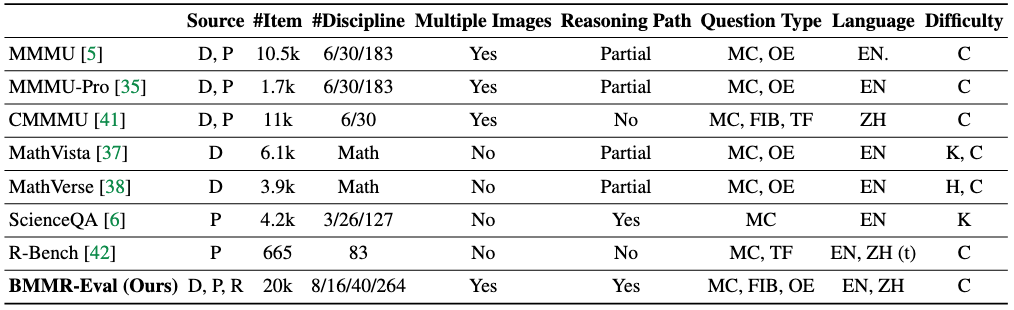
Overall comparison between BMMR-Eval and other existing benchmarks. In the Source column, D means digital-based data sources, such as websites and existing datasets; P means print-based data sources, such as college textbooks and exams; R means repurposed data sources. The column Multiple Images implies the presence of questions that contains multiple images. In the Question Type column, MC means multiple-choice questions, FIB means fill-in-the-blank questions, ans OE means open-ended questions, TF means true-or-false questions. (t) in the Language column means ''translated''. In the Difficulty column, C means college level, K means K-12 level, and H means high-school level. Information for R-Bench only cover its multimodal subset. For all datasets, we only report statistics on their test split.
Statistics
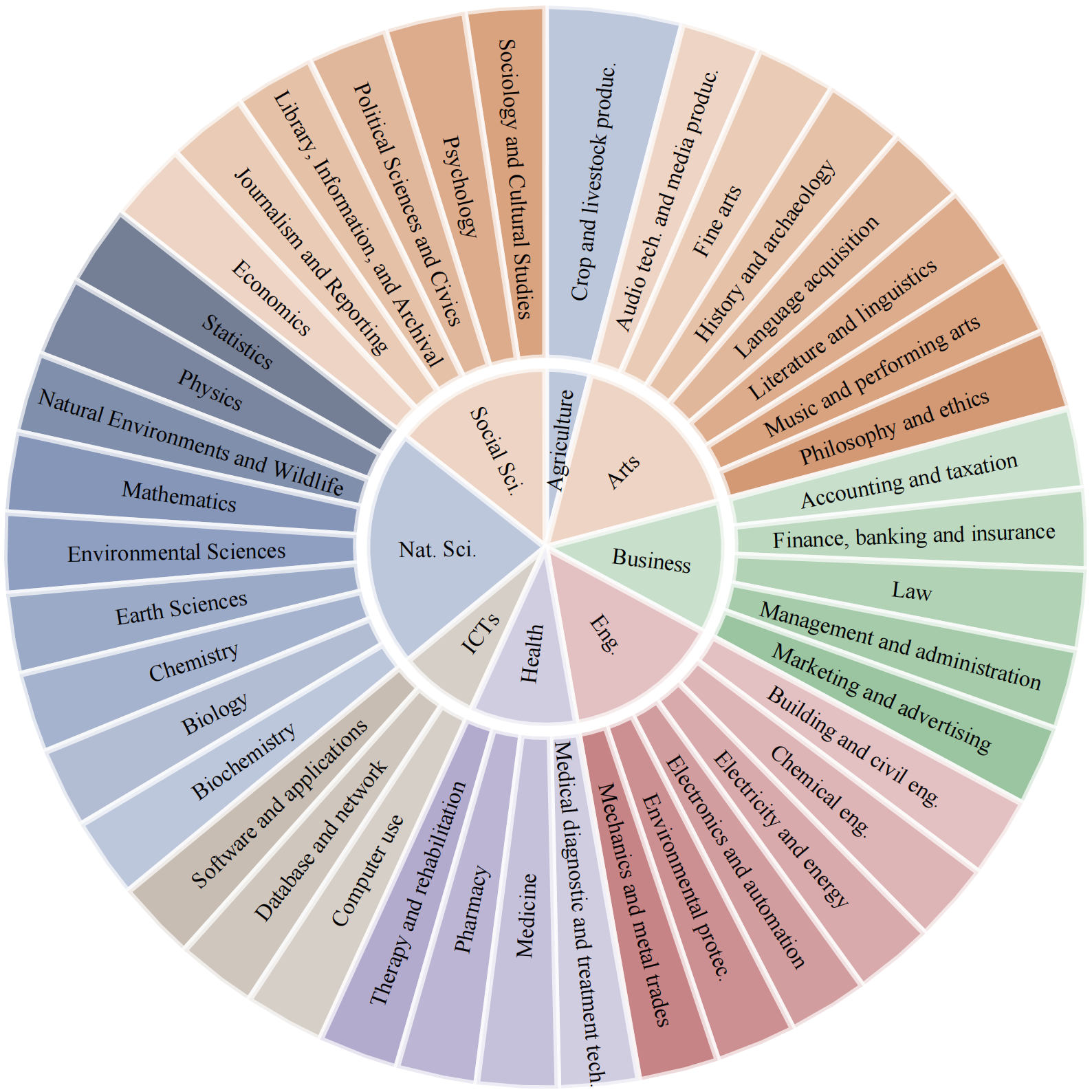
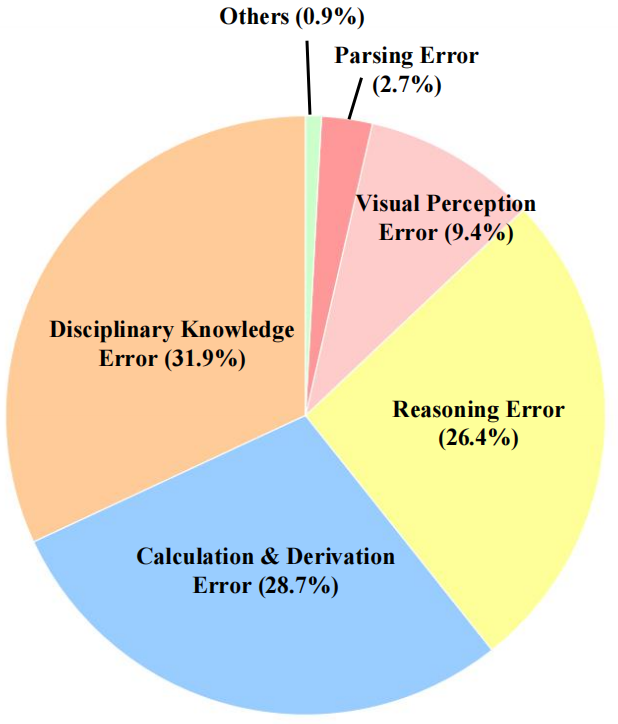
Subject distribution of the BMMR Dataset
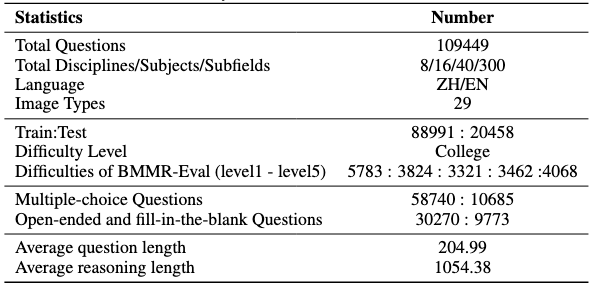
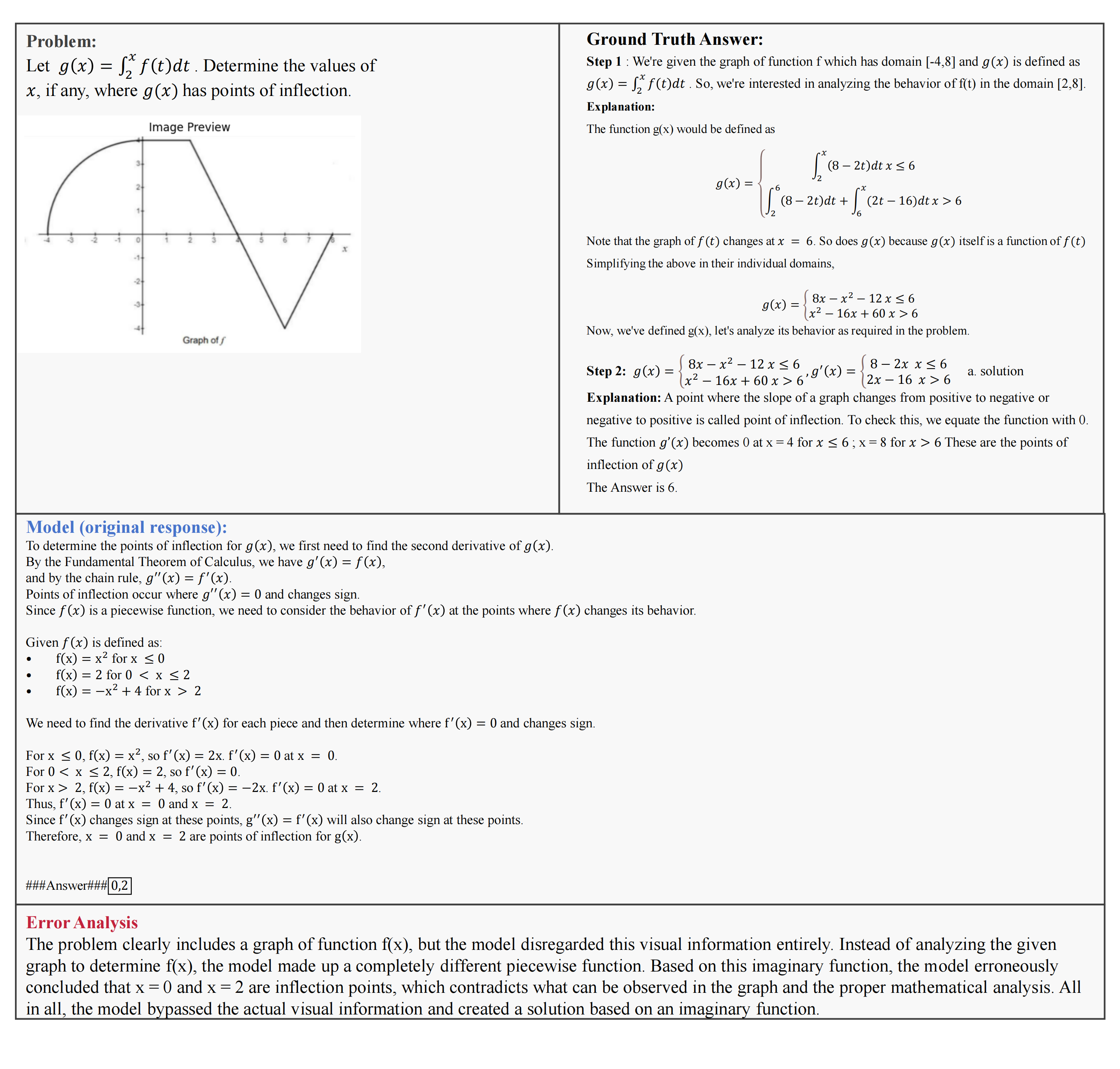
Key statistics of the BMMR Dataset